Data Pipeline Agentic System
A multi-agent system that turns natural language into safe, accurate data queries — connecting every major data source a business runs on, and replacing manual SQL and reporting entirely.
Role: Team Lead Type: AI Agent Systems · Data Engineering Built For: Internal client deployment Timeline: 2025–2026 Stack: LangGraph · LangChain · SQLAlchemy · sqlglot · ChromaDB · sentence-transformers · dbt · PostgreSQL · Salesforce · HubSpot · Google Sheets

The Problem
The client’s analytics workflow had a structural bottleneck: every data question went through one person.
Non-technical teams submitted requests. That person wrote SQL, pulled from Salesforce, cross-referenced Google Sheets, formatted the output, and sent back a report — two days later. By then the question had usually changed.
On top of that, their data lived across five disconnected systems. Getting a unified answer meant manually joining PostgreSQL records with CRM data and spreadsheet logs. Nobody had built the bridge. Every report was a one-off.
We were brought in to make that the last manual report they’d ever need to run.
What We Built
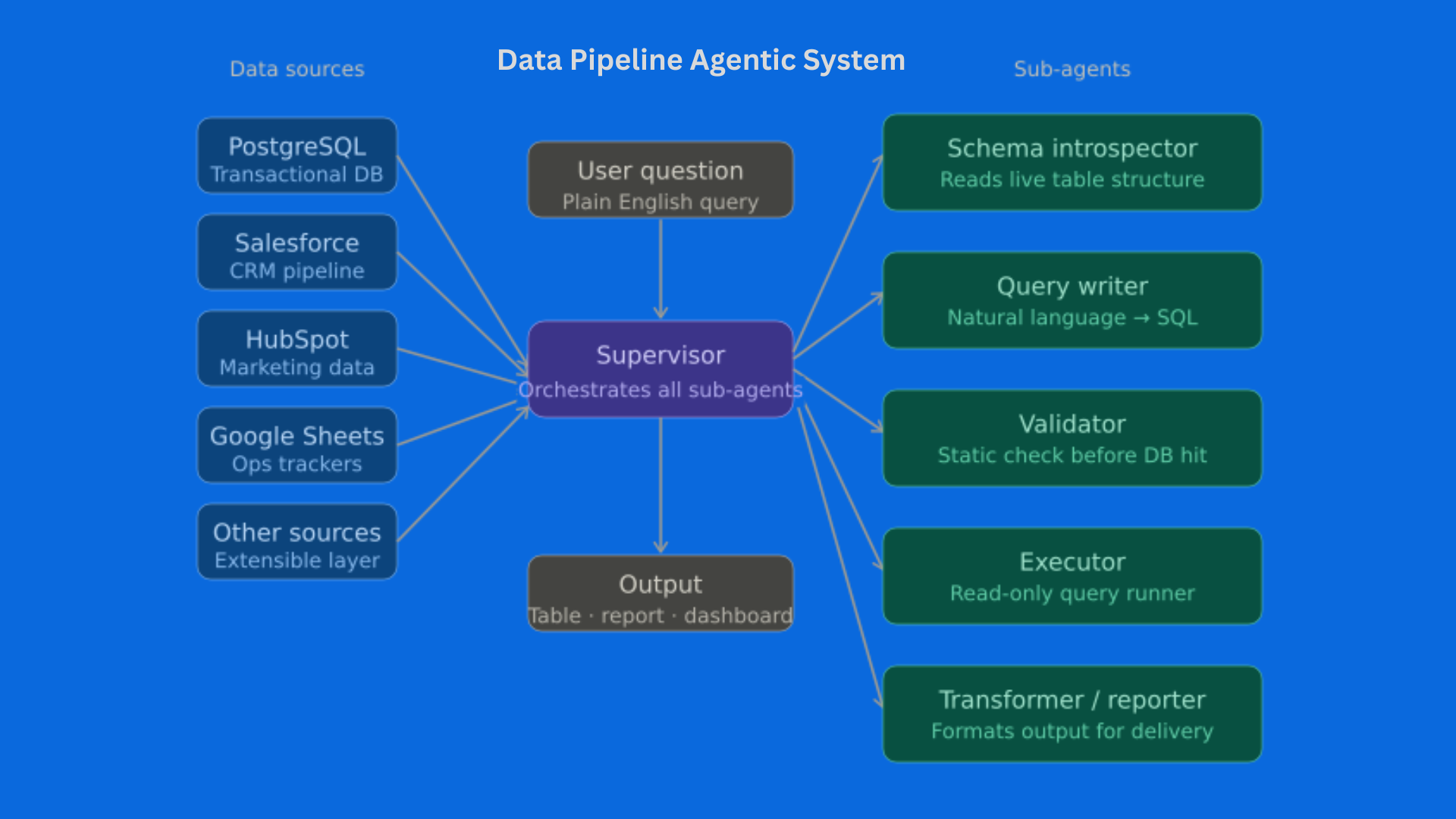
A supervisor-orchestrated graph of specialized sub-agents, each owning exactly one concern. The supervisor decides which sub-agent runs next based on the current state of the request — it’s not a single model answering questions, it’s a coordinated system with defined responsibilities at every step.
The five sub-agents:
Schema Introspector — Before any query is written, this agent reads the live structure of every connected data source: table names, column names, data types, and relationships. The query writer always has accurate, up-to-date context. No guessed column names, no hallucinated table references.
Query Writer — Takes the user’s plain-English question and the schema context and produces a precise query. For large databases, it uses semantic search to find only the relevant tables — keeping the context lean and the output accurate.
Validator — Every query is parsed and checked for errors before it touches any database. If something is wrong, the error feeds directly back to the Query Writer for an automatic fix. No failed queries reach live data.
Executor — Runs the validated query against the appropriate data source through a read-only connection. If execution fails despite validation, the error loops back again. The system self-corrects.
Transformer / Reporter — Takes raw results and formats them into whatever the user actually needs: a summary, a table, a dashboard-ready dataset, or a structured report ready for distribution.
Data Sources Connected
The agent connects to all of the client’s data simultaneously — something no previous tool had done:
| Source | What It Provides |
|---|---|
| PostgreSQL | Core transactional and operational data |
| Salesforce | Pipeline, deal stages, account records, activity logs |
| HubSpot | Marketing data, contact records, campaign performance |
| Google Sheets | Financial models, manual trackers, operational logs |
| Additional sources | Connected via the same pipeline architecture |
A question like “show me monthly revenue by product for Q1, broken down by region and compared to our pipeline forecast” — which previously required four separate manual pulls and a spreadsheet merge — now returns in a single query.
How It Flows
When a user asks a question:
- The schema introspector reads live structure from all connected sources
- The query writer generates a precise query with full context
- The validator checks it — if wrong, it loops back automatically
- A human-in-the-loop checkpoint shows the query before it runs — approval required
- The executor runs it against the appropriate source via read-only connection
- The reporter formats and delivers the output
The retry loop is what makes this reliable in production. Errors are caught before they reach the database, fed back into the system, and corrected — without any human involvement in the debug cycle.

Key Capabilities
Schema-Aware Querying For databases with dozens of tables, the system uses semantic search to find only the relevant tables at query time. Only those land in the query writer’s context. This keeps accuracy high even across large, complex schemas.

Multi-Source in a Single Query The agent can join data across PostgreSQL, Salesforce, and Google Sheets in one response. No manual export, no spreadsheet merge, no waiting.
Safety by Design Three independent safety layers run before any query reaches a live database — static validation, operation filtering, and enforced read-only connections. Non-technical users can query freely without risk of affecting live data.

Human-in-the-Loop Checkpoint Before execution, the agent surfaces exactly what it’s about to run and waits for approval. For routine queries this is lightweight. For anything going to an external report or client-facing output, a human sees and approves the query first.
Self-Improving Models Frequently-asked queries get promoted into permanent, versioned data models via the dbt integration. Questions that get asked every week become reusable, maintained assets — the system improves the data infrastructure as it’s used.
Technology Inventory
| Layer | Tools |
|---|---|
| Agent Orchestration | LangGraph |
| LLM & Prompt Layer | LangChain |
| Schema Inspection | SQLAlchemy |
| Query Validation | sqlglot |
| Vector Store | ChromaDB |
| Embeddings | sentence-transformers |
| Data Modeling | dbt-core |
| Databases | PostgreSQL · Salesforce API · HubSpot API · Google Sheets API |
Result
Manual SQL and reporting was eliminated entirely.
Teams that previously submitted requests and waited days now ask questions directly and get answers in seconds. The analyst who ran every report now works on higher-value problems. Reports that were rebuilt manually every week are now generated on demand, consistently, from a single source of truth across all connected systems.
What I’d Do Differently
The semantic schema retrieval depends on having good descriptions written for each table and column. Where those descriptions were thin, retrieval quality dropped and query accuracy followed. I’d now treat schema documentation as a first-class deliverable at the start of any engagement — before a single agent node is built.
AI Agent Systems · Data Engineering · Multi-Source Intelligence LCBYTELAB — 2025–2026